典型的なデータサイエンス・コースでは、自己組織化マップ(SOM: Self-Organizing Maps)は、データ可視化、次元削減、クラスタリングおよび探索的データ分析の手法として紹介される。あまりにたくさんの目的で使用できるため、結局何に使えばよいのか焦点が定まりにくい。したがって、今日のデータサイエンス・プロジェクトでは補完的なツールとして取り扱われがちだ。このポストでは、SOMが高度なアンサンブル・モデルの構築において重要な役割を果たすことを説明したい。
アンサンブル手法とは何か?
機械学習にはさまざまな手法があり、それぞれ長所と短所がある。あらゆる問題、あらゆる種類のデータに適用できる単一の手法は存在しておらず、適材適所でさまざまな手法を用いることが重要であると考えられている。それはしばしば「ノーフリーランチ定理」と関係づけられて説明されているが、厳密に言うと、ノーフリーランチ定理は事前知識の活用の重要性に関係している。それはともかく、モデルの性能を上げるためには、単一のモデルよりも複数のモデルを組み合わせることが効果的である。
機械学習で複数のモデルを組み合わせるアプローチは、アンサンブル・テクニックと呼ばれる。機械学習のコンペで上位にランクされるモデルは、階層化された十数個以上のモデルからなると言われている。機械学習プロセスは、しばしばPythonライブラリを用いてコードされるが、もし個別の機械学習手法を基本的な方法で使用するだけなら、Pythonにこだわるのはあまり意味がない。データ サイエンティストのタスクは、ライブラリから利用できるさまざまな機能を組み合わせて一連のパイプラインを構築することであり、その中でもアンサンブル手法が中心となる。
アンサンブル手法は、トップクラスのデータ サイエンティストが競い合って開発しており、決まった形式はないが、一般的に次の 3 つのタイプが説明されている:
バギング
バギング(Bagging)は、”Bootstrap AGGregatING”の略である。ブートストラップは、ランダム・サンプリングによって標本分布を推定する統計手法である。複数のトレーニング・データがランダムに選ばれて、予測器/分類器を作成するために使用される。すべての結果を収集して、最終決定がなされる。予測器では平均値が、分類器では多数意見が採用される。
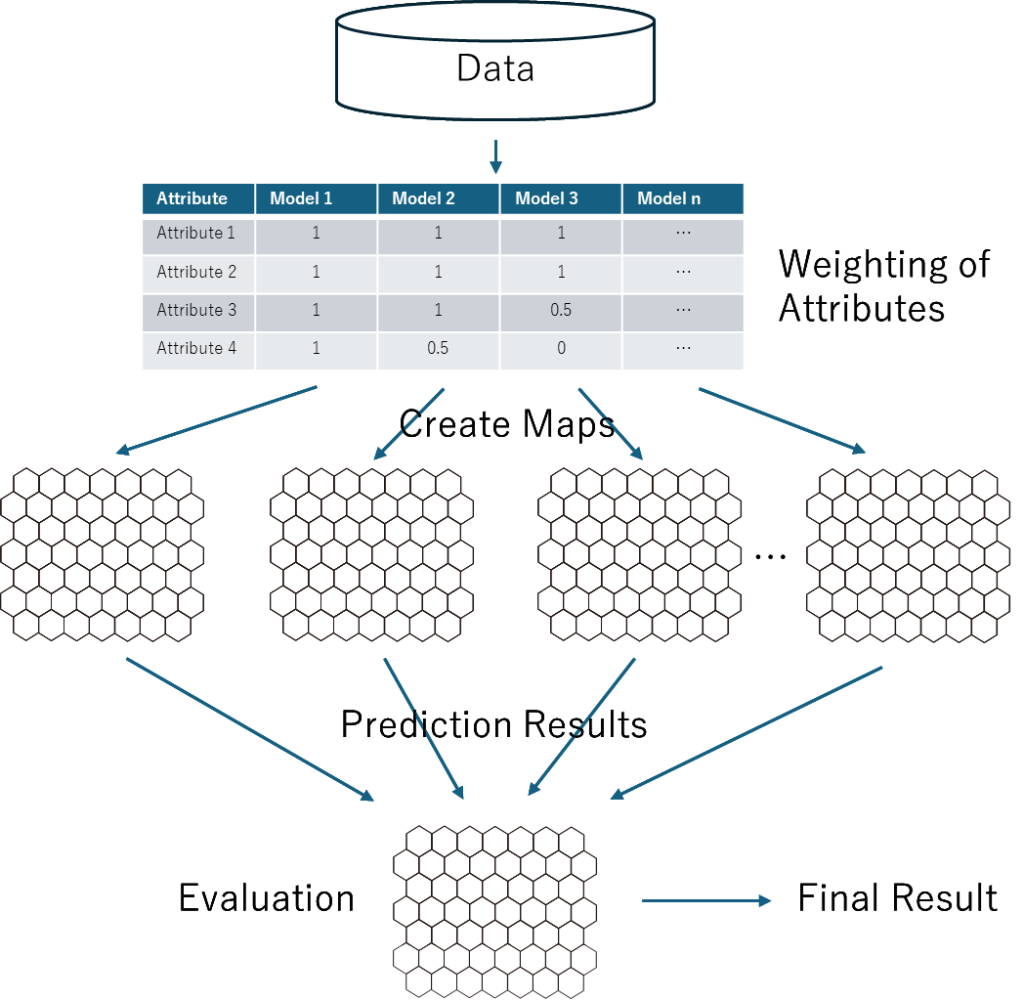
バギングは最も簡単な手法なので、広く使われている。一般的なバギングでは、各属性をモデルに投入するか否かの選択だけがなされ、最終結果は平均値または多数決のようなとても単純な決定である。バギングの一般的な事例に、ランダムフォレストがある。
それとは対照的に、SOMをバギングに使用する場合、各属性に重みを与えることができる。言い換えるなら、0が「除外」で1が「投入」であるのに加えて、0.5とかの中間の重みを与えることができるということだ。さらに、最終結果を判断するときに、マップの各領域の正答率や誤答率に基づいて、各モデルが高い性能を持つ局所空間の結果のみを使用することができる。これは私が2000年代の初めに使ったテクニックであり、当時、私は「アンサンブル」という用語も知らなかったし、周囲の人たちもまだそれに気づいていなかった。(ただし、私はランダム・サンプリングの代わりに、実験計画法を使って重みを割り当てていた。)
ブースティング
ブースティングは、最初の基本モデルの残差または誤答率を次のモデルのターゲット属性として用いて、モデルの性能を上げるテクニックである。より精度の高い予測結果を得るために、最初のモデルの予測結果と2番目のモデルの予測結果を統合する。このプロセスが最終結果を得るまで繰り返される。したがって、これは計算集約的なテクニックである。
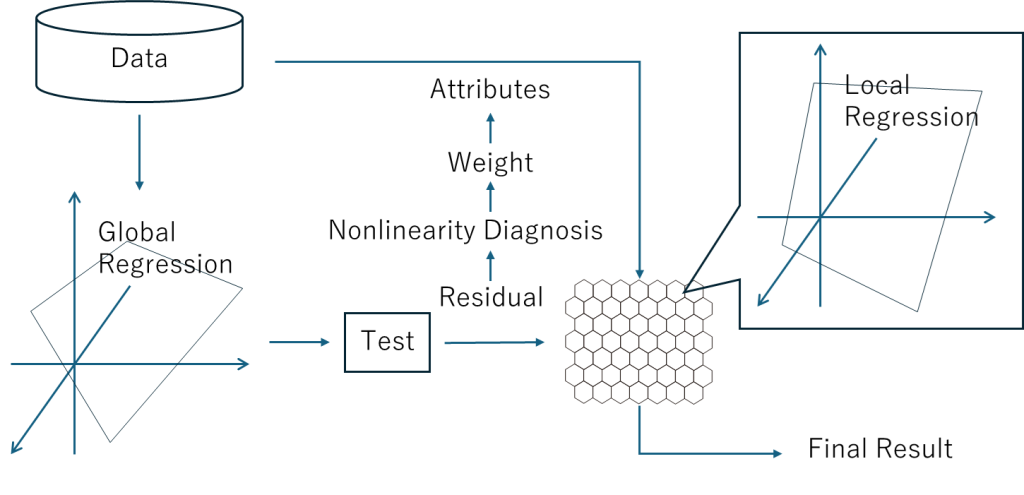
ViscoveryのSOMローカル回帰法は、この一例であると見なされる。これは2003年に Viscovery Predictorという製品として市場投入された。当時の価格は、コンサルティングを含めて、約50,000ユーロだったと記憶している。これもアンサンブルとかブースティングという用語は使わずに説明されていた。
まず最初に線形回帰モデルを作成して、その残差を2番目の回帰モデルを作成するための新しいターゲット属性として用いる。ただし、2番目および その後の回帰モデルは、SOMの各ノードで構築される。各ノードに受容野が設定され、ノードからの距離に応じて重みが減じられながらデータレコードが収集される。また、各属性の非線形性が診断され、それに応じて属性の重みづけが更新される。結果として、SOMローカル回帰法は、1000個以上の回帰モデルを使用することができる。
このような高度なアンサンブル手法が2003年に開発されたことは、じつに驚異的である。 GoogleやAmazon、Microsoftのような企業がデータサイエンス市場に参入してきたのずっと後のことであり、Viscoveryは市場よりも2歩も3歩も先に進んでいた。率直に言って、 Viscoveryのビジネスがそれほど成功したとは言えない。2000年代に一時的に成功はしたものの、2010年頃からデータサイエンス市場が勢いづいてからは、Pythonを標準とするデータサイエンスのトレンドからは取り残された感は否めない。
データ サイエンスでは、データ サイエンティストが Python でパイプラインを自由にコーディングできるが、Viscovery は自動化されたワークフローを早期に提供することで先走りし、結果としてパイプラインが固定されてしまった。しかし、SOM ローカル回帰法は、SOM を使用するアンサンブル手法の強固なフレームワークを定義し、時代を超えた手法として残っている。(この手法は、世界最大の自動車メーカーで長年採用され続けていることで実用性が証明されている。)
スタッキング
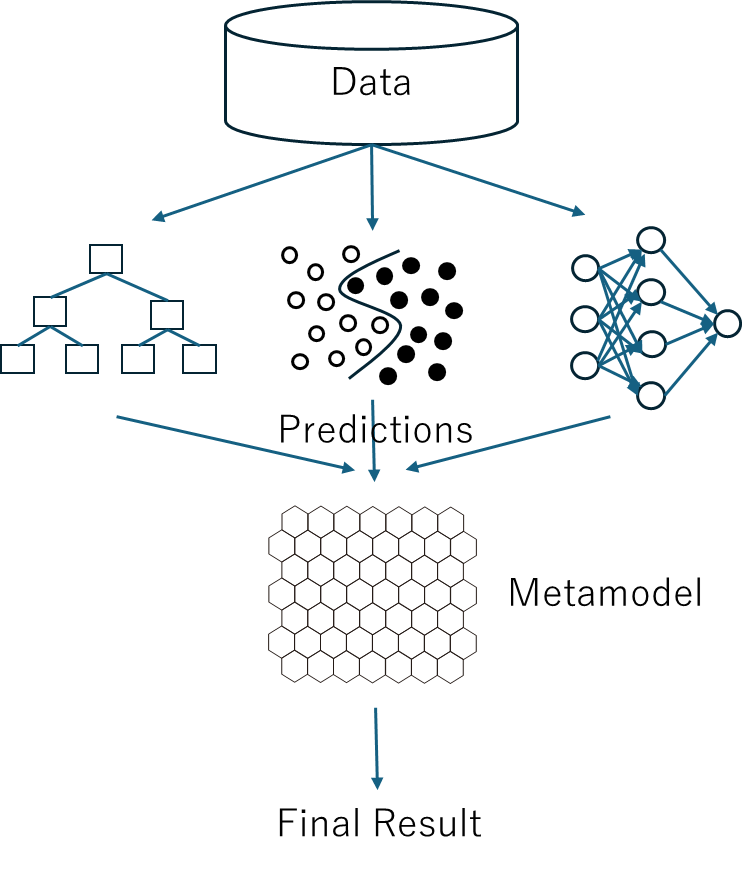
スタッキングは、最も高度で有望なアンサンブル・テクニックであると考えられる。機械学習には勾配ブースティングモデル(CBM: Gradient Boosting Models)、ニューラルネットワーク(NN: Neural networks)、因数分解マシン・モデル(FM: Factorization Machines Models)、サポートベクターマシン(SVM: Support Vector Machines)、ロジスティック回帰(LR: Logistic Regression)など さまざまなアルゴリズムがある。最初に、それらを別々に用いて予測を行い、次にそれらの予測結果を新しい入力として用いて、メタモデルを作成する。
つまり、メタモデルは、多数の単一モデルからの予測結果の多次元データ空間でのパターンを学習し、状況に応じて最良の予測結果を採用する能力を獲得する。我々は、このメタモデルにSOMを使用することを提案する。バギングのところで説明したように、SOMは局所空間での各モデルの正確さや誤答率を識別できるので、各モデルが適切なところで使用でき、最良の性能を達成できる。 たとえるなら、個性あふれるトップ・アイドル級の個人を集めてグループを結成したようなもので、各メンバーはそれぞれが最も輝くパートを歌うようなものだ。
ノーコード・アンサンブル機械学習の加速
現在、「機械学習を始めたいなら、まずはPythonを勉強すべき」という風潮が広がっているが、この風潮は今後変わっていくだろう。これは、LLM(大規模言語モデル)の進歩によりコーディングの自動化が進み、ノーコードやローコードへとトレンドがシフトしているためだ。そもそも Python が必要な理由は、複雑なタスクを自動化するためであり、ノーコードとローコードの波がこの分野を席巻している。機械学習の初心者が、お決まりのスクリプトを書いて、シンプルな機械学習モデルを構築し、データ サイエンティストと名乗れた時代はもう終わった。
Viscovery SOMine がアンサンブル機械学習の中核となるための条件はすでに整っている。個別の機械学習モデルを簡単に構築できるようになった。場合によっては、GUI 環境で機械学習モデルを構築するためのツールも簡単に提供できる。これらの機械学習モデルの予測とテスト結果を収集し、Viscovery SOMine でメタモデルを構築するのは簡単だ。これは現在でも可能だが、将来的には Viscovery SOMine がこの関連機能を拡張することが大いに期待される。