LLMの進展が背景
ご存じのとおり、近年LLM(大規模言語モデル)技術によって、コンピュータが人間と会話できるようになりました。人間が自然言語でコンピュータに指示をすると、コンピュータがその意思をくみ取って、適切なアクションを起こすということが現実になろうとしています。今後数年以内にAIエージェントが商品化され、ビジネスが劇的に効率化されたり、日々の生活の中でAIによるサポートを受けることが急速に広がることでしょう。
LLMがなぜ人間と会話できるようになったのか?その秘密の1つがベクトル化にあります。言葉をベクトル(=数値の配列)で表現することによって、コンピュータが言葉を<計算>できるようにしたのです。ベクトルは足し算、引き算などの演算ができます。例えば、「女性」というベクトルと、「王様」というベクトルがあって、それを足し算すると「女王」のベクトルになるという具合です。逆に「女王」から「女性」を引くと「王様」になります。
このベクトルの次元数は、LLMのモデルによって異なるますが、通常、数千次元の意味空間を構成しています。LLMはあらゆる単語をベクトル化しており、その結果、見かけ上異なる言葉を使っていても、似た意味の文字列は、超多次元の意味空間の中で、近くに配置されるようになります。通常、長いテキストは、数100字程度の「チャンク」と呼ばれるテキストに分割して、テキスト・チャンクごとにベクトルを計算します。このようなテキスト情報のベクトル化のことを業界では、埋め込み(Embedding)と呼んでおり、得られるベクトルのことを埋め込みベクトル(Embedding Vector)と呼んだりします。
このようにしてテキスト・チャンクとその埋め込みベクトルの対をデータベース化しておくと、テキスト・チャンク同士の意味空間での距離を計算できます。すなわち、距離の近いテキスト・チャンクは、お互いに類似した意味を持っていると判断できます。ユーザーが自然言語でLLMに質問をすると、LLMがその質問に関連する情報を回答することができる仕組みは、ざっくり言うと、このようなベクトルのマッチングによって成り立っています。
これを利用して、最近では既存の大手ITベンダーがテキスト情報の類似検索を売り出したりしています。ただし、テキストを入力すると、その類似テキストが出てくるだけでは、全体像を把握しにくいという限界があります。それを克服するために、埋め込みベクトルのデータベース全体を次元削減して、2次元(原理的には3次元も可能)の座標にプロットして解釈する方法もあります。t-SNEおよびUMAPという次元削減手法が注目されています。しかし、哀しいかな、座標上に数千、数万のポイントが散らばっていると、人間にはその1つ1つを識別することは容易ではありません。
SOMによるテキスト情報のマッピング
そこで現在注目を集めているのがSOMです。SOMは埋め込みベクトルとの相性がじつに良いのです。なぜならSOMもLLMを構成する人工ニューラルネットワークと同様、多変量データをベクトル*として取り扱っていて、データレコードをその類似性によって並べる能力を有しているからです。
視覚的には2次元のマップができますが、次元の情報は切り捨てられません。SOMの各ノードは、学習するデータと同じ次元を厳密に保っています。マップの面は、データ空間の位相的(トポロジカルな)順序を表していて、見かけ上平面に見えますが、多次元空間内ではデータの密度分布に沿って自由曲面を描いています。
ただし、SOMのノードは、多次元空間内で離散的に(飛び飛びに)配置されており、したがって、SOMが切り捨てているのは、データレコードのローカルなバラツキということになります。同じノードに複数のデータレコードが対応する場合、それらはいくらかのバラツキを持っていますが、データセット全体の観点からみると、それらの差異を無視することが許容できるほど類似しているので、1つのノードに対応しているのです。見方を変えてこれを解釈するなら、データ圧縮ともなります。
SOMのノードは、いくつかのデータレコードを連れながら並んでいます、ノードが持つベクトルを使って、ノードをクラスタリングすることができます。得られたクラスタ内のノードに対応するデータは、統計的に共通の特徴を持っているので、結果的にSOMはコンセプト(概念)の構造を表現していることになるのです。ちなみに論理学では、概念は外延と内包によって定義されます。外延とは概念に含まれる実体(あるいはメンバー)であり、内包とはそれらが持つ共通の特性です。
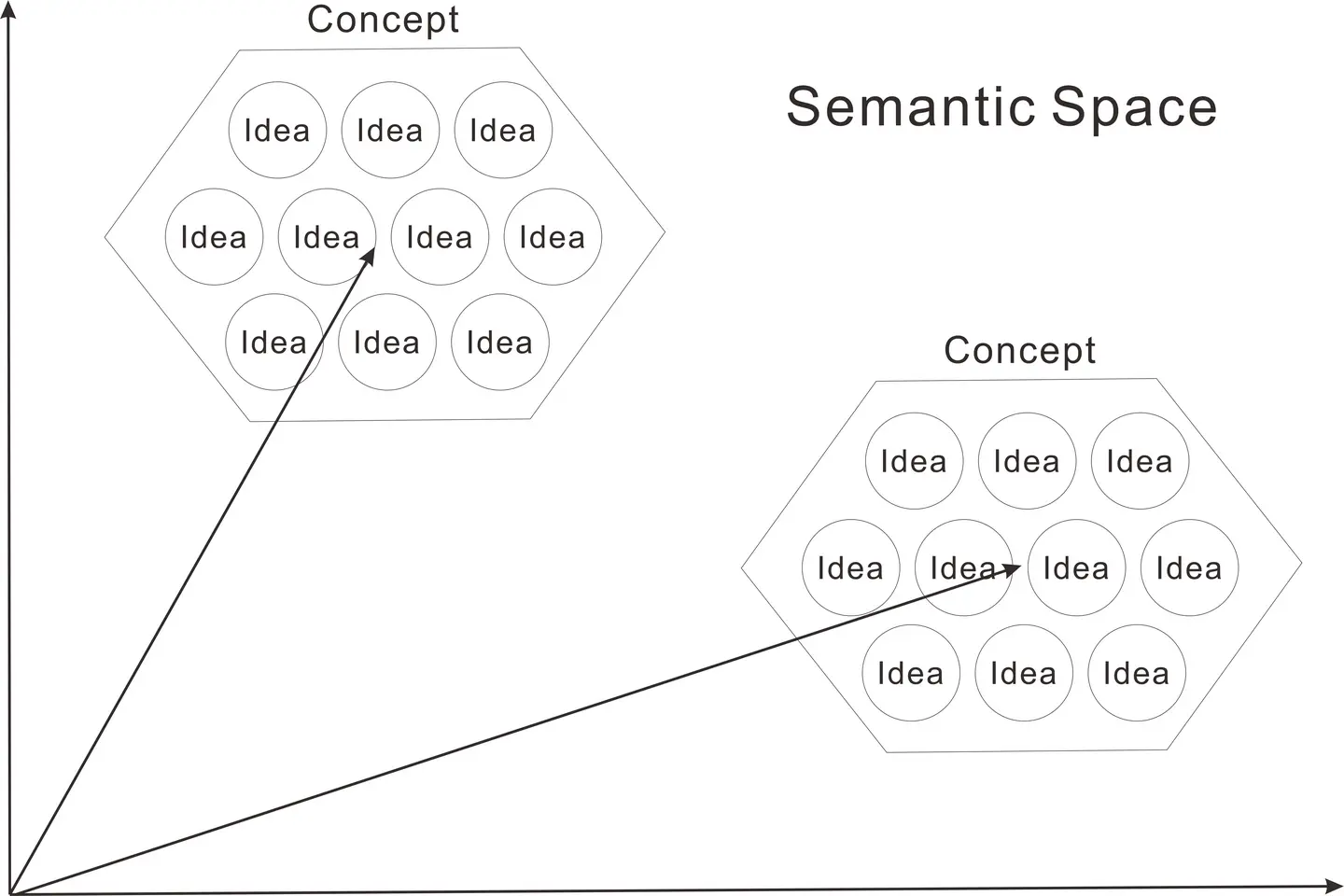
したがって、テキストの埋め込みベクトルをSOMで学習すると、学習に用いたテキストの集合に内在する概念構造を表現するコンセプト・マップが現れます。これは現在利用可能などの手法と比較しても強力な手法です。なぜなら、SOMは埋め込みベクトルを学習したマップにさらに、テキストに付随する情報を連合(連想)させることができるからです。たとえば、テキストから抽出したキーワードの有無行列を連合させると、その値がそれぞれのノードに追加されます。Viscovery SOMineでは強力なプロファイル分析の機能があり、マップの各領域でのキーワードの強度を統計的に分析できます。
SOMを使ったテキストマイニングは、20年以上昔から研究はされてきましたが、LLMの進展によって、こうした分析が強力かつ手軽に行える環境が整ったことは誠に喜ばしいことです。
*注意:ここでいう「ベクトル」とは広い意味での多次元配列を指します。平たく言えば、多変量データの1行分だと思って間違いありません。中学ぐらいで「ベクトル量」「スカラー量」というのを習うので、「ベクトル」というと真っ先に「向きと大きさを持った量」を思い浮かべる人が多いので、ちょっと誤解が生じやすいようです。多変量データの各列の数値はスカラー量と考えて差し支えありませんが、その複数列を一括して取り扱うと多次元となって、それをベクトルと呼びます。ざっくりした言い方をすると、データサイエンスの文脈でベクトルとか行列というのは、データを塊で計算する数学的方法です。ニューラルネットワークやSOMでは、多次元データを取り扱っているので、入力データを「入力ベクトル」と言ったりします。