Innovation Mapsは、世界に向けて発信しておりますので、普段は英語で発信しておりますが、日本のお客様にも知って頂きたいので、今日は例外的に日本語でお届けします。
Innovation Mapsは、これからの社会を大きく変容させる主要な技術革新テーマについて、ニュース記事や技術論文を自己組織化マップ(Viscovery SOMine)でマッピングしてお届けしております。
方法は常に改良されていくかと思われますが、今のところ、以下のような方法でマップを提供しております:
データ準備
(1)ニュース記事、技術論文をインターネットからスクレイピング(収集および構造化データの抽出)する。
(2)記事のタイトル・要約(論文はアブストラクト)をEmbedding Vecotrsに変換する。
(3)Embedding VectorsをPCAで次元削減する。–>Visual Explorer用マップ
(4)事前に定義された数10個の特徴から記事のタイトル・要約(論文はアブストラクト)に含まれる特徴を抽出する。
(5)記事のタイトル・要約(論文はアブストラクト)に含まれる用語を抽出して、ダミー変数(0と1の値の表)を作成する。–>Enterprise Data用マップ
Embedding Vectorについて
自然言語処理を効率化するためにEmbedding Vectors(埋め込みベクトル)が最近よく使用されるようになっています。基本的な考え方は、機械学習で入力データを正規化してベクトル値に変換し、それを主成分分析などで次元削減するようなことの延長のようです。ChatGPTなどの大規模言語モデルで、どのようなテキストでもベクトル値に変換できる汎用的なAPIが提供されているので、本プロジェクトでもそれを使用します。
OpenAI APIが提供するEmbedding Vectorsは、1536次元の値を持っており、その値自体を人間が解釈することはできません。Embedding Vectorsは、テキストや文書を分類するには、たいへん便利なのですが、結果を解釈するのが難しいという問題があります。世間で出回っているEmbedding Vectorの解説でも、2次元のグラフ上にマッピングして、「分類ができた」と言って喜んで終わっています。実践的であるためには、もう一歩が必要です。
もう1つ、クラスタリングや分類の問題で理解しておくべき最も重要なことは「醜いアヒルの仔の定理」です。Embedding Vectorを使っても分類に失敗する本当の理由は、すべての次元を完全に平等に扱うことが「客観的」だと思い込んでいることにあります。ほとんどの人々はここでつまづいています。「分類」とは、我々が生物として生きるために必要から生じている「方法」であることに気づけば、重みづけの重要さが理解できます。
そこで、我々は高次元データを解釈するために自己組織化マップを使用します。自己組織化マップも2次元にマッピングしますが、多次元の情報も保持されて成分マップ(Viscoveryでは属性ピクチャと呼ぶ)として利用できます。自己組織化マップ(Viscovery SOMine)は、1536次元のデータでも十分学習が可能で、きれいに文書を分類することができます。しかし、それをそのまま人間が見てもやはり理解できないので、我々はEmbedding Vectorsをさらに次元圧縮して15次元の主成分得点を使用することにしました。実験の結果、これで十分、文書を分類することができ、かつ、テキストから抽出した特徴や用語との相関を観察するにも(人間のためには)ちょうどよい次元数となります。
テキストから抽出した特徴や用語から直接、マップを作成しても良いのですが、抽出の仕方によっては偏りができてしまい、完全な網羅性というのが保証できません。その点で、Embedding Vectorsはプロジェクトを効率化するために欠かせません。解釈可能性と完全性の両立のために、我々はEmbedding Vectors、PCA、SOMを組み合わせて使用します。
Visual Explorer用プロジェクト・ファイルの作成
無償モジュールVisual Explorerでは、入力できるデータの列数が100までに制限されているため、この範囲で表示できるマップを作成します。Visual Explorer用プロジェクトでは、我々はEmbedding Vectorsをさらに次元削減して得た15次元の主成分得点でマップを作成して、ニュース記事や論文、アイデアなどが分類されているところをお見せします。
ユーザーはマップを探索して、類似する記事や論文、アイデアに素早くアクセスできます。必要に応じて、各主成分への重要度の設定を変えることにより、異なるマップの順序付け(並び方)を見ることもできます。これは、KJ法でのグルーピングと同様なこととして考えることができます。まさに、これが他の手法に対するViscovery SOMineの強みでもあります。
Cluster and Classify + Enterprise Data用プロジェクト・ファイルの作成
Viscovery SOMineの製品ライセンスをお持ちのユーザー様には、追加で抽出した特徴や用語に関するダミー変数を含む完全なプロジェクト・ファイルを提供できます。これを用いると、本格的なマップの探索、マイニングが可能になります。
脳-コンピュータ・インタフェースのイノベーション・マップ
マップの事例として、脳-コンピュータ・インターフェースのマップを掲載します。本来、Viscovery SOMineは数100万件のビッグデータをマッピングすることも可能な能力を持ちますが、脳-コンピュータ・インターフェースに関しては、記事が20個程度しか収集できなかったので、はじめてSOMをご覧になる方にも理解しやすいマップになったかと思います。なお、今回は、特徴や用語の抽出はしませんでした。
Viscovery SOMinenの有料ライセンスをお持ちですと、Data Records Windowから、各ノードや領域、クラスタなどに対応するデータ・レコードにアクセスできるので、マップにレコード・ラベルを貼るやり方は推奨しておりませんが、このケースでは、記事のラベルを貼って解釈することが簡単です。
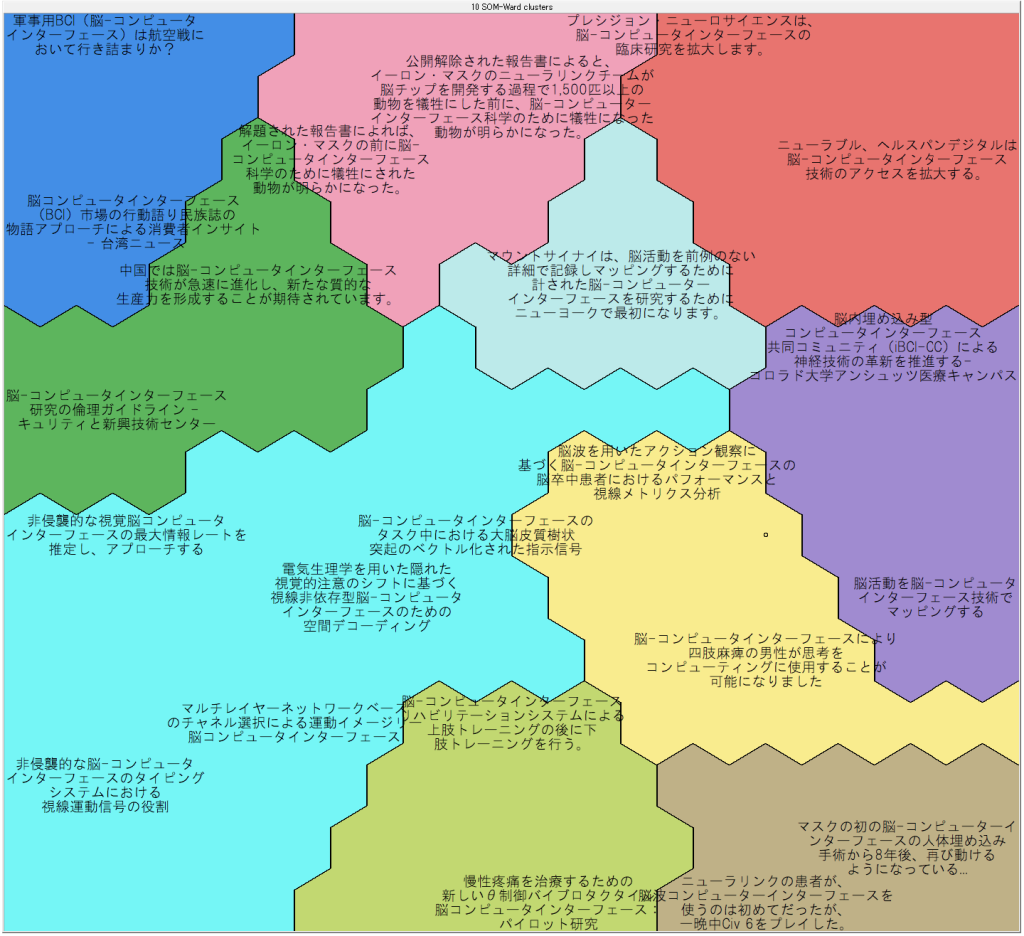 Embedding Vectorsから作成したマップ
Embedding Vectorsから作成したマップ
いかがでしょうか?(日本語のラベルは自動翻訳によるもので、不自然なのはご容赦ください。)類似したニュース記事が近くに位置するように組織化されているのがわかるとかと思います。誤解のないように言うと、これはほんの序の口で、より本格的なことを英語ブログの方でやっております。しかし、もし記事が数千、数万あったとしても効率よく類似の記事にアクセスできることはイメージして頂けるかと思います。Visual ExplorerユーザーのためにPCsで作成したマップも掲載します:
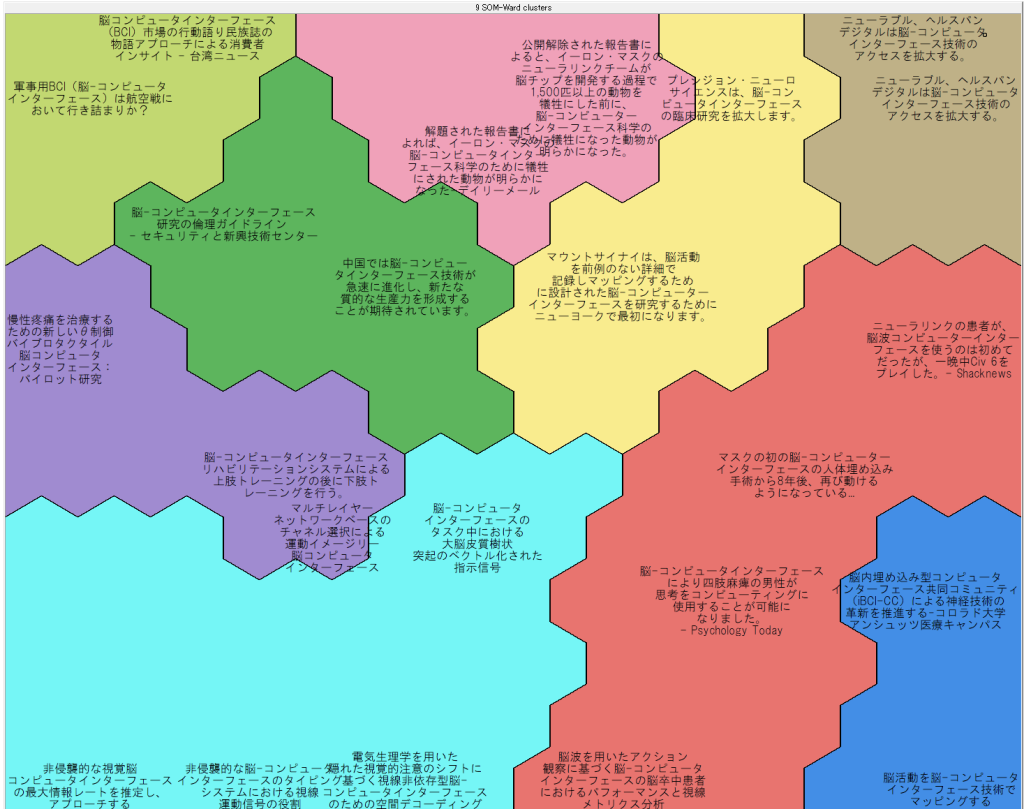 主成分得点から作成したマップ
主成分得点から作成したマップ
上のマップとは部分的に並び方が違っていますが、概ね似たようなマップが得られているのがわかります。ただし、これを得るには寄与度の低いPCの影響を下げるように、各PCにかける重要度を調整しています。
今回、最も注目度の高い(複数メディアで掲載件数が多い)ニュースは、イーロン・マスクのニューラルリンクが、四肢麻痺の29歳の男性患者の脳にインタフェースを埋め込んで、男性がコンピュータ・ゲームをできるようになったというニュースでした。これに関連する記事がマップの右下の方に集まっています。
またマップの上部中央からやや左に、ニューラルリンクが1500匹以上の動物を犠牲にしたという記事があります。
さらなる分析
有料ライセンス会員の皆さまは、Viscovery SOMineのプロファイル分析機能によって、各クラスタや各領域の特徴を分析することができます。さらにクラスタリングのもとに、(KJ法のように)自在にセグメンテーション・モデルを作成することができ、それをデータに適用して、各記事の分類結果をデータとして出力できます。
出力した分類結果データをどのように使用するかというと、たとえば、それを使って、さらにベイジアン信念ネットワーク(BBN)でモデルを構築できます。BBNでも各セグメントでの各属性(用語)の値を確率でみることができ、それはViscovery SOMineでのプロファイル分析を別の表現方法にしたもと解釈できます。そして、さらに、各属性の値を入力して(つまり、用語が含まれるかどうかを指定して)、その組み合わせがどのセグメントを結果するかを(これも)確率で見ることができます。これはSOMではできないことです。BNNのツールとしては、HuginがBNNのパイオニアであり、世界最高の技術水準を今日も保っております。マインドウエア総研にお問い合わせください。
ビューア:
f無償のソフトウェア・モジュールViscovery SOMine Visual Explorerで上記のマップを表示できます。日本語版はこちらからダウンロードできます(Windows 10 or higher required)。
SOMファイル:
マップ・ファイルはこちらからダウンロードできます。ただし、元となるデータマートを含んでおりませんので、探索や分析にはいくらかの制限があることにご注意ください。