マインドウエア総研 多田薫弘(ただくにひろ)
前回は(1) 架空の20種類のポテトチップスの試食体験を食レポ風のリッチなテキストにして、(2)その埋め込みベクトルを取得して、(2)そこからUMAPという次元削減手法を使って3次元の因子を抽出して、(3)それを自己組織化マップ(SOM)で学習することにより、ポテトチップスの意味マップを作成し、(4)LLMを使って因子を解釈したり、意味マップの任意の空間を選択して、新しい商品のコンセプトを探索できることを紹介しました。それは官能評価分析におけるPreference Mappingと呼ばれる手法の前段であるInternal Preference Mappingに似た分析と言えます。Preference Mappingでは官能特性を数値化するので、それでは表現しきれない複雑な情報は切り捨てられるのに対して、提案手法では自然言語を使ってリッチな情報を取り扱うことができます。またPreference Mappingでは、PCAの第1、第2主成分の2軸しか使わないのに対して、SOMを使うことでそれ以上の因子を使って、より情報損失の少ないマッピングができることを示しました。
消費者のクラスタリング
さて次のステップとして、前回と同じ20種類のポテトチップスに対する消費者の評価スコアをクラスタリングします。従来の方法では、消費者を適度な数のグループに分けるために、一般的な階層クラスタ分析を使うのですが、そこから何も知見を得られていないのが、とても残念な点です。我々は、SOMを使って消費者を2次元に並べ、さまざまなクラスタ数を選んで消費者の空間を探索することができます。
Viscovery SOMineというデータマイニング・システムでは、「プロファイル分析」の機能があり、マップ上の任意の領域を選択してインタラクティブに(効率的に)多重比較検定を行うことができます。そこから得られる知見によって、「どの領域の消費者をターゲットにするか」という戦略を練ることができます。データマイニングの真骨頂は、じつはこの辺にあるのですが、世間の人々がこれを理解するレベルに到達するのは容易ではなさそうです。
提案手法ではLLMを活用して十分に細分化されたクラスタの特徴を解釈することにより、ターゲット領域の発見をより手軽にしたいと考えます。
ここに200人の消費者が20種類のポテトチップスを5段階で評価した架空データを用意しました。これをSOMでクラスタリングします。ただし、SOMの順序付けに寄与させるのは、1人ひとり消費者ごとに、各人の評点の合計が1になるように正規化した数値を使い、元のスコアは順序付けに寄与しない追加属性として与えます。得られたマップの画像を以下に掲載します:
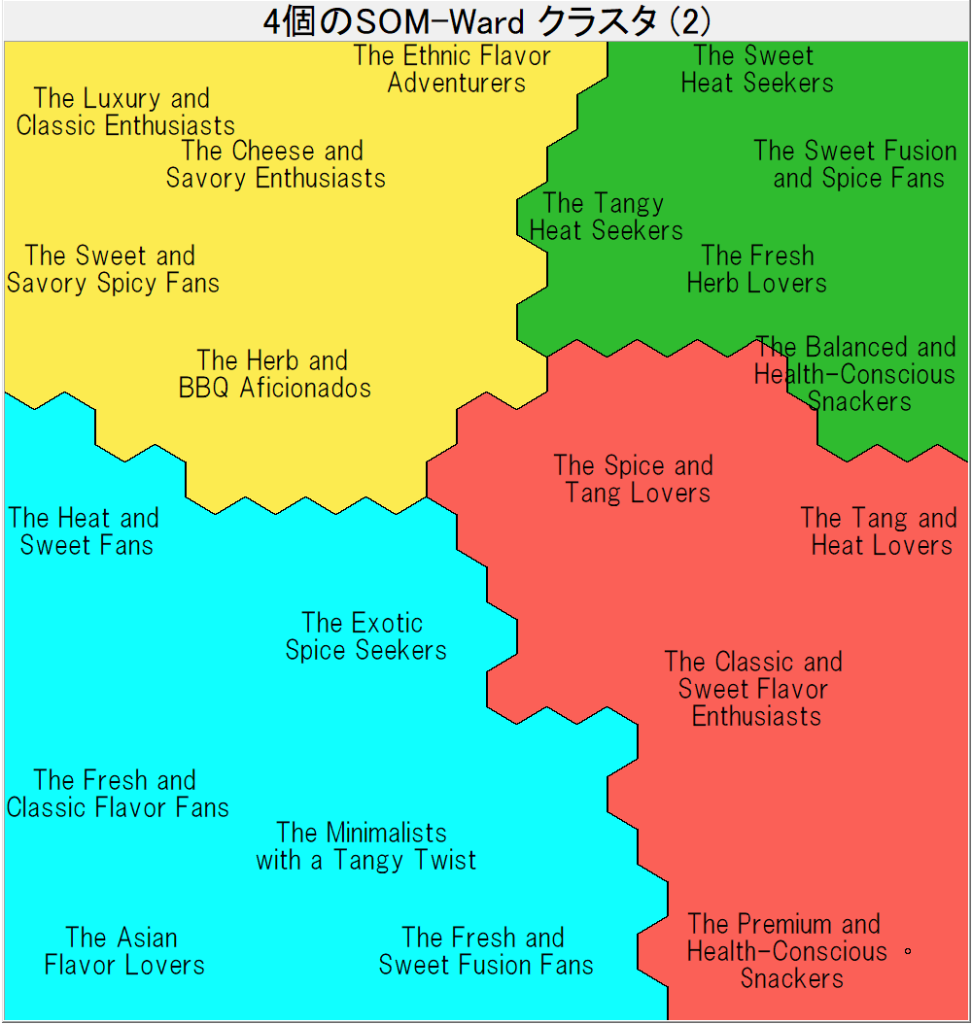
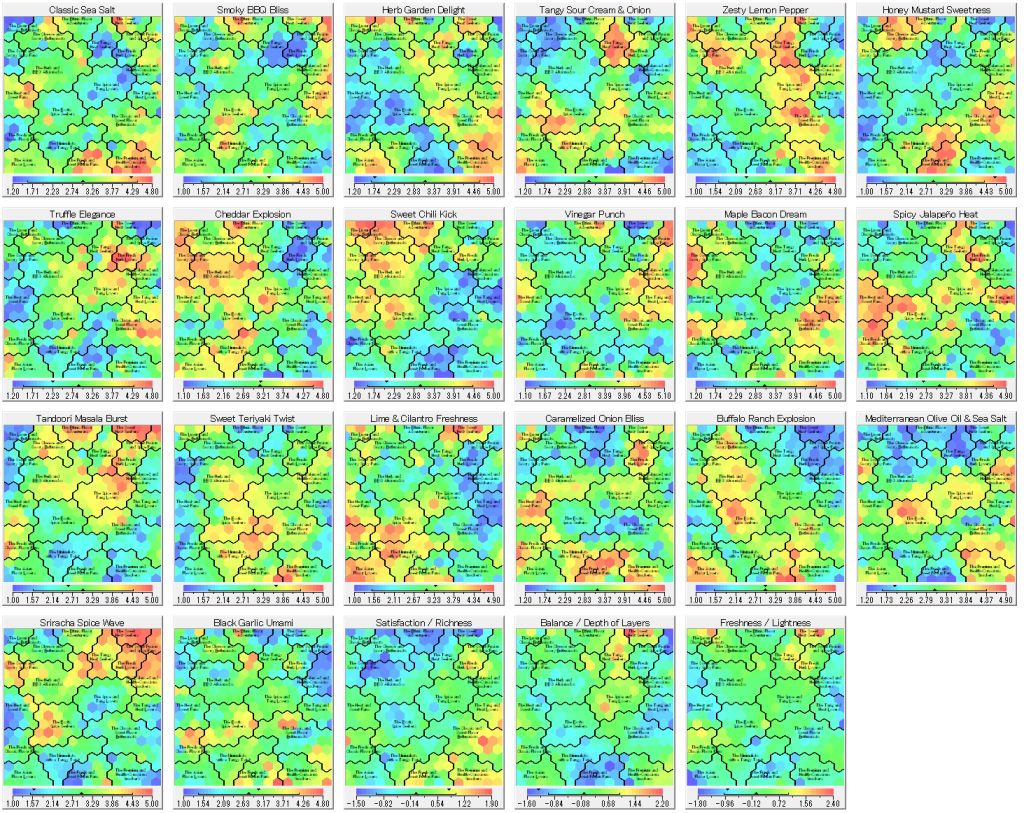
クラスタリングの品質指標は、クラスタ数4が最も高いです。それはそれで全体の有意なクラスタを理解する助けにはなりますが、商品企画では商品間のローカルな差異に注目するべきなので、より細分化されたクラスタリングを見るべきです。ここではクラスタ数20を選びました。この結果をLLMに提示して解釈した結果が以下です:
C1: クラシックで甘い味を愛する人たち
- トップスナック:
- クラシックシーソルト、メープルベーコンドリーム、ハニーマスタードスイートネス
- 解釈:
このクラスターは、クラシックな塩味と甘いプロファイル、特にベーコンとメープルの組み合わせやハニーマスタードの香りを好む。馴染みがありながら贅沢な味を好む傾向が反映されている。(全文はこちら)
最終の目的は商品を企画開発することですから、ここで消費者の空間を探索して、ターゲットを定義します。詳細はコンサルティングが必要ですが、方法はカラースケールを使って、特性値の範囲を指定することにより、ノードが絞り込まれます。実験では、下記のノードを選択しました:
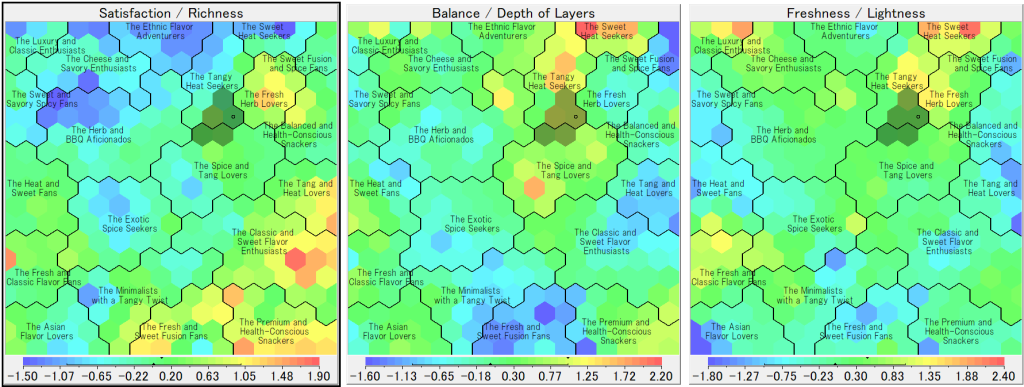
製品マップへの融合
従来のPreference Mappingでは、消費者の選好パターンを最初のInternal Preference Mappinngと融合させるために、Internal Preference Mappingの第Ⅰ、第2主成分を説明変数として、各製品への選好スコアのクラスタ平均を目的変数として、交互作用項つきの線形回帰でクラスタごとにモデルを作成します。線形回帰ではありますが、交互作用を使うことで曲面モデルを作成するのですが、単純な2次方程式になるので人工的であり、たとえ比較する製品が数100個あっても正確なモデルになりそうもありません。ここが従来のPreference Mappingの最大の問題点です。
我々はSOMを使って自由曲面でモデルできますので、より現実的で自然なモデルを構築できます。
一昨年、日本官能評価学会の分科会にお呼ばれしたときには、専門家のスコアと消費者のスコアをリンクさせるために、2つの行列が同じ製品数を共有しているので、行列の積を計算することで、消費者の各官能特性に対する「反応」を数値化できるという見解を示しましたが、今回は別のアプローチをとります。
我々はSOMを使用するので、SOMの順序づけに寄与する属性以外に追加の属性を連想させることができます。これを利用して、消費者のスコア行列を転置して、元のマップに連合させることができるので、消費者1人ごと、クラスタ平均、ターゲット領域など、自由に見たい対象のスコアが元のマップの上でどのように分布するかを見ることができます。これにより、最終的にPreference Mappingの目的と一致した分析ができると考えます。
以下が消費者のスコア行列を転置して、元の製品マップに連合させたマップで、前のステップで定義したターゲット領域でのスコアを表示したものです。Preference Mappingで言えば、最終のマップに相当します。Preference Mappingでは人工的な平面または曲面のモデルでしたが、SOMではとても変化に富んだ曲面が作成されていることがわかります。
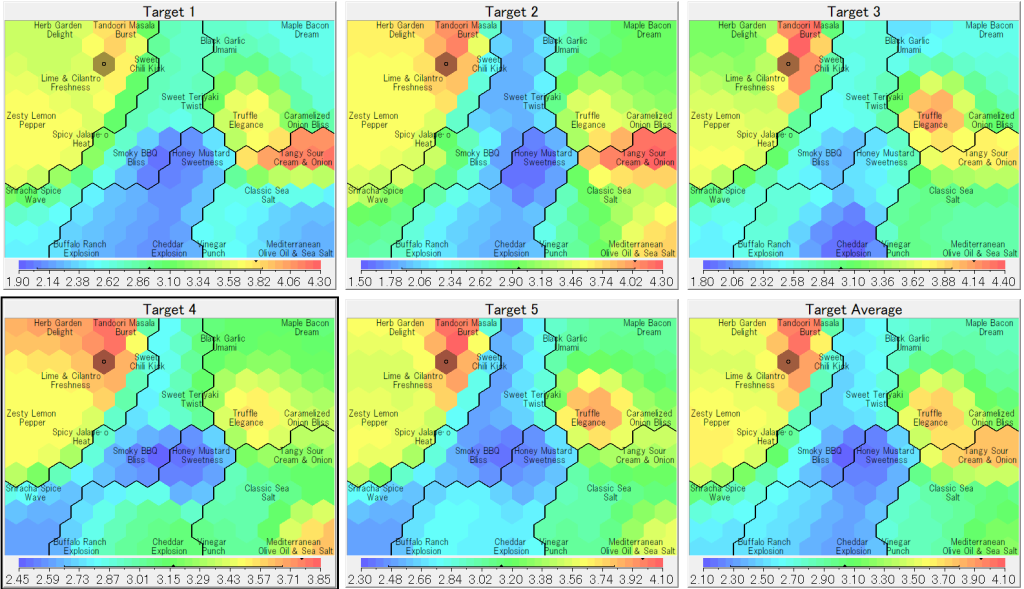
赤く表示されたノードがスコアの高い特性空間を表すので、そこからなるべく既存製品と差別化できそうなところを選んで、商品コンセプトを決定することになります。実験では暗くシェーディングされているノードを選んで、そのノードのUM1, UM2, UM3の数値を再びLLMに提示して、コンセプトを質問しました。その回答が下記です:
数値の特徴
- UM1: 7.62 → 中程度の満足度・リッチネス
- 味の濃厚さや満足感は高すぎず、軽すぎない絶妙なバランス。万人受けしやすい濃厚感を示します。
- UM2: 9.46 → 非常に高いバランス・味の深み
- 味わいが多層的で複数の要素がうまく調和していることを示唆します。甘み、塩味、酸味などがバランス良く絡み合い、単調ではありません。
- UM3: -0.03 → 軽やかさよりも少しリッチ・重厚
- 爽やかさや軽さは控えめで、深みや旨味が中心。スパイシーさやリッチなフレーバーが期待されます。
商品コンセプト: 「スパイスハニー・コンプレックス」
フレーバーの特徴
このフレーバーは 「甘さと複雑なスパイス感」 が融合した一品です。
- 最初に広がるのは、ハチミツ の優しい甘みと滑らかなコク。
- その後、クミン、ガーリック、ブラックペッパーなどの 複数のスパイス がじわじわと口の中に広がり、単調さを感じさせません。
- 後味には、軽いピリッとした刺激が残り、甘さとスパイシーさのコントラストが絶妙なバランスを生み出します。
見た目
金色に輝くチップスに、黒胡椒とハーブの細かなフレークが散りばめられ、見た目からも洗練された印象を与えます。
ターゲット層
- 大人向けの味わい を楽しみたい方
- 複雑で深みのあるフレーバーを求める方
- 甘さとスパイシーさの両方を楽しみたいグルメ志向の消費者
キャッチコピー
「甘くてスパイシー、クセになる贅沢なひととき。」
このコンセプトは、UM1で程よい満足感を提供し、UM2の多層的な深みを生かしつつ、UM3が示唆する重厚感とリッチさをうまく取り入れたバランスの良い商品設計となっています。
引用終わり
まとめ
従来のPreference Mappingは、専門家による製品の官能評価と、消費者による製品の選好度をリンクさせて分析するために、(1)官能特性の数値化、(2)PCA、(3)クラスタ分析、(4)線形回帰を組み合わせていますが、率直に言って、そのやり方では各段階でそれぞ情報損失があって、信頼できるモデルを作成するのは難しそうです。
我々は(1)LLMを活用することで、定型の数値データ以外に自然言語で表現されたテキストを使用して、情報の機微を漏らさずモデルに取り込むことができること、(2)SOMを活用することで、データ空間を直感的に探索でき、かつ自由曲面による自然なモデルを構築できることを示しました。
今回は、従来的な数値化された官能評価データを使用しませんでしたが、SOMは異種のデータを統合することができるので、今回示した方法と従来の方法をSOMの上で統合することも可能です。意欲ある企業様と共同でそのような事例を開発できる機会をお待ちしております。
コメントを残す